Starting from the 2019 version, an automatic statistical model building algorithm is implemented in Monolix: SAMBA (Stochastic Approximation for Model Building Algorithm)
SAMBA is an iterative procedure to accelerate and optimize the process of model building by identifying at each step how best to improve some of the model components (residual error model, covariate effects, correlations between random effects). This method allows to find the optimal statistical model which minimizes some information criterion in very few steps. It is described in more details in the following publication:
At each iteration, the best statistical model is selected with the same method as the Proposal. This step is very quick as it does not require to estimate new parameters with SAEM for all evaluated models. Initial estimates are set to the estimated values from the Proposal.
The population parameters of the selected model are then estimated with SAEM, individual parameters are simulated from the conditional distributions, and the log-likelihood is computed to evaluate the improvement of the model. The algorithm stops when no improvement is brought by the selected model or if it has already been tested.
Initialization
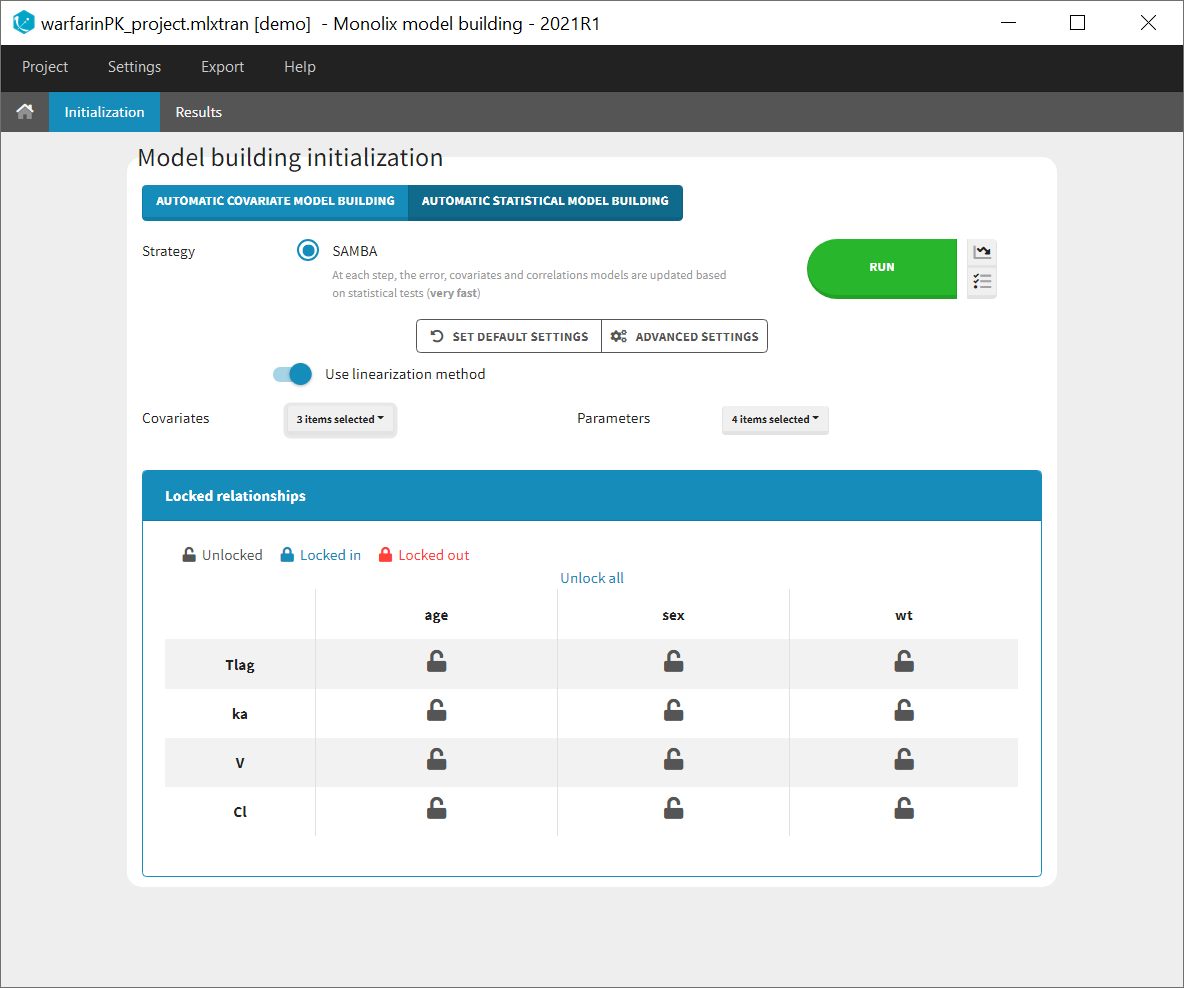
Settings
The linearization method is selected by default to compute the log-likelihood of the estimated model at each iteration. It can be unselected to use importance sampling.
The improvement can be evaluated with two different criteria based on the log-likelihood, that can be selected in the settings (available via the icon next to Run):
- BICc (by default)
- LRT (likelihood ratio threshold): by default the forward threshold is 0.01 and the backward threshold is 0.01. These values can be changed in the settings.
Starting from the 2021 version, all settings used are saved and reloaded with the run containing the model building results.
Selecting covariates and parameters
It is possible to select part of the covariates and individual parameters to be used in the algorithm:

Moreover, a panel “Locked relationships” can be opened to lock in or lock out some covariate-parameter relationships among the ones that are available:
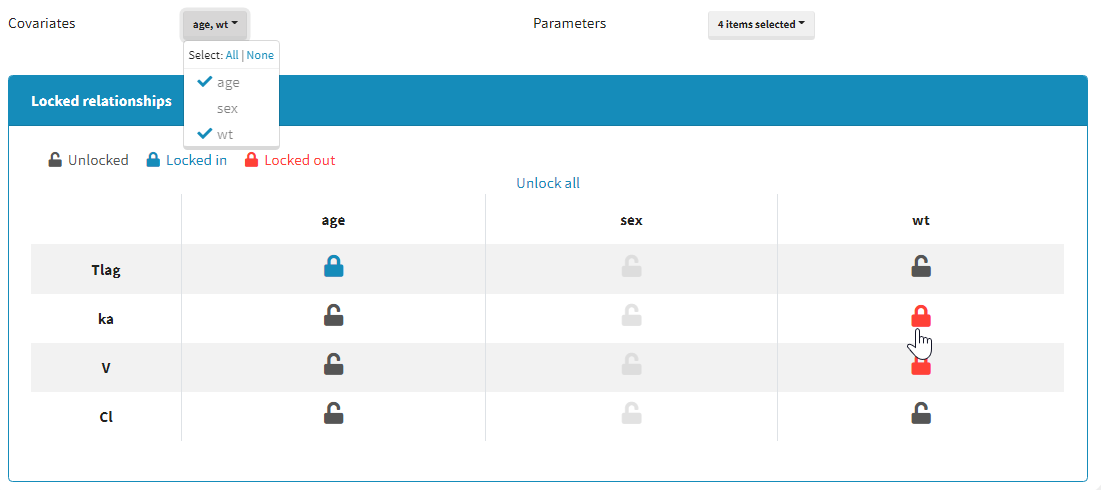
Starting from the 2021 version, all relationships considered in model building are part of the settings which are saved and reloaded with the run containing the model building results.
Results
The results of the model building are displayed in a tab Results, with the list of model run at each iteration (see for example the figure below) and the corresponding -2LL and BICc values.
All resulting runs are also located in the ModelBuilding subfolder of the project’s result folder (located by default next to the .mlxtran project file).
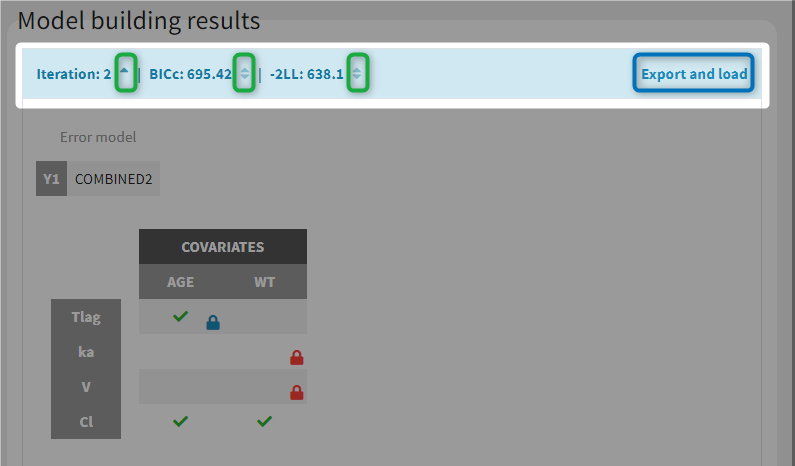
In the Results tab, by default runs are displayed by order of iteration, except the best model which is displayed in first position, highlighted in blue.
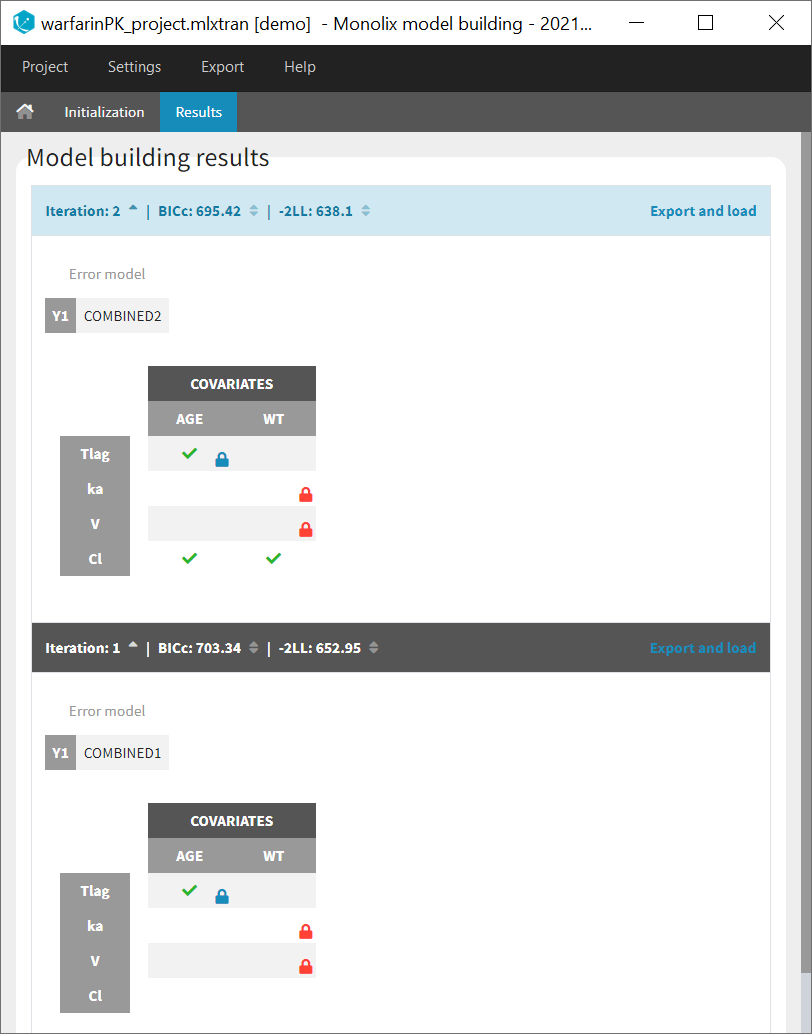
Note that the table of iterations can be sorted by iteration number or criteria (see green marks below). Buttons “export and load” (see blue mark below) can also be used to export the model estimated at this iteration as a new Monolix project with a new name and open it in the current Monolix session.
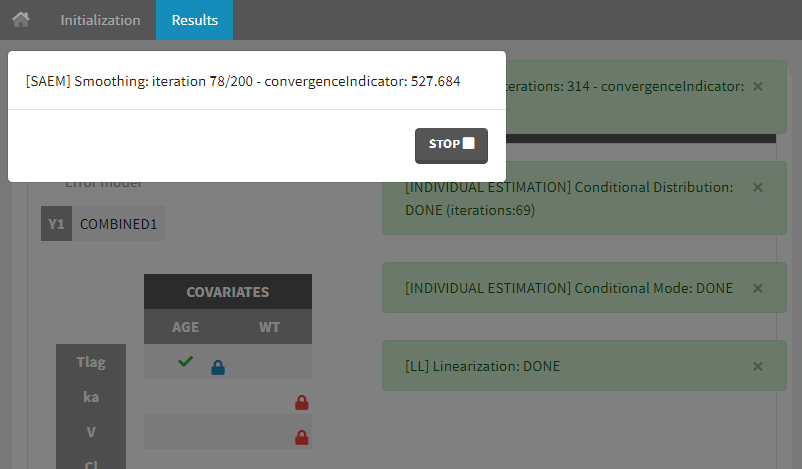
While the algorithm is running, the progress of the estimation tasks at each iteration is displayed on a white pop-up window, and temporary green messages confirm each successful task.