Purpose
The log-likelihood is the objective function and a key information. The log-likelihood cannot be computed in closed form for nonlinear mixed effects models. It can however be estimated.
Log-likelihood estimation
Performing likelihood ratio tests and computing information criteria for a given model requires computation of the log-likelihood
$$ {\cal L}{\cal L}_y(\hat{\theta}) = \log({\cal L}_y(\hat{\theta})) \triangleq \log(p(y;\hat{\theta})) $$
where \(\hat{\theta}\) is the vector of population parameter estimates for the model being considered, and \(p(y;\hat{\theta})\) is the probability distribution function of the observed data given the population parameter estimates. The log-likelihood cannot be computed in closed form for nonlinear mixed effects models. It can however be estimated in a general framework for all kinds of data and models using the importance sampling Monte Carlo method. This method has the advantage of providing an unbiased estimate of the log-likelihood – even for nonlinear models – whose variance can be controlled by the Monte Carlo size.
Two different algorithms are proposed to estimate the log-likelihood:
- by linearization,
- by Importance sampling.
Log-likelihood by importance sampling
The observed log-likelihood \({\cal LL}(\theta;y)=\log({\cal L}(\theta;y))\) can be estimated without requiring approximation of the model, using a Monte Carlo approach. Since
$${\cal LL}(\theta;y) = \log(p(y;\theta)) = \sum_{i=1}^{N} \log(p (y_i;\theta))$$
we can estimate \(\log(p(y_i;\theta))\) for each individual and derive an estimate of the log-likelihood as the sum of these individual log-likelihoods. We will now explain how to estimate \(\log(p(y_i;\theta))\) for any individual i. Using the \(\phi\)-representation of the model (the individual parameters are transformed to be Gaussian), notice first that \(p(y_i;\theta)\) can be decomposed as follows:
$$p(y_i;\theta) = \int p(y_i,\phi_i;\theta)d\phi_i = \int p(y_i|\phi_i;\theta)p(\phi_i;\theta)d\phi_i = \mathbb{E}_{p_{\phi_i}}\left(p(y_i|\phi_i;\theta)\right)$$
Thus, \(p(y_i;\theta)\) is expressed as a mean. It can therefore be approximated by an empirical mean using a Monte Carlo procedure:
- Draw M independent values \(\phi_i^{(1)}\), \(\phi_i^{(2)}\), …, \(\phi_i^{(M)}\) from the marginal distribution \(p_{\phi_i}(.;\theta)\).
- Estimate \(p(y_i;\theta)\) with \(\hat{p}_{i,M}=\frac{1}{M}\sum_{m=1}^{M}p(y_i | \phi_i^{(m)};\theta)\)
By construction, this estimator is unbiased, and consistent since its variance decreases as 1/M:
$$\mathbb{E}\left(\hat{p}_{i,M}\right)=\mathbb{E}_{p_{\phi_i}}\left(p(y_i|\phi_i^{(m)};\theta)\right) = p(y_i;\theta) ~~~~\mbox{Var}\left(\hat{p}_{i,M}\right) = \frac{1}{M} \mbox{Var}_{p_{\phi_i}}\left(p(y_i|\phi_i^{(m)};\theta)\right)$$
We could consider ourselves satisfied with this estimator since we “only” have to select M large enough to get an estimator with a small variance. Nevertheless, it is possible to improve the statistical properties of this estimator.
For any distribution \(\tilde{p_{\phi_i}}\) that is absolutely continuous with respect to the marginal distribution \(p_{\phi_i}\), we can write
$$ p(y_i;\theta) = \int p(y_i|\phi_i;\theta) \frac{p(\phi_i;\theta)}{\tilde{p}(\phi_i;\theta)} \tilde{p}(\phi_i;\theta)d\phi_i = \mathbb{E}_{\tilde{p}_{\phi_i}}\left(p(y_i|\phi_i;\theta)\frac{p(\phi_i;\theta)}{\tilde{p}(\phi_i;\theta)} \right).$$
We can now approximate \(p(y_i;\theta)\) using an importance sampling integration method with \(\tilde{p}_{\phi_i}\) as the proposal distribution:
- Draw M independent values \(\phi_i^{(1)}\), \(\phi_i^{(2)}\), …, \(\phi_i^{(M)}\) from the proposal distribution \(\tilde{p_{\phi_i}}(.;\theta)\).
- Estimate \(p(y_i;\theta)\) with \(\hat{p}_{i,M}=\frac{1}{M}\sum_{m=1}^{M}p(y_i | \phi_i^{(m)};\theta)\frac{p(\phi_i^{(m)};\theta)}{\tilde{p}(\phi_i^{(m)};\theta)}\)
By construction, this estimator is unbiased, and its variance also decreases as 1/M:
$$\mbox{Var}\left(\hat{p}_{i,M}\right) = \frac{1}{M} \mbox{Var}_{\tilde{p_{\phi_i}}}\left(p(y_i|\phi_i^{(m)};\theta)\frac{p(\phi_i^{(m)};\theta)}{\tilde{p}(\phi_i^{(m)};\theta)}\right)$$
There exist an infinite number of possible proposal distributions \(\tilde{p}\) which all provide the same rate of convergence 1/M. The trick is to reduce the variance of the estimator by selecting a proposal distribution so that the numerator is as small as possible.
For this purpose, an optimal proposal distribution would be the conditional distribution \(p_{\phi_i|y_i}\). Indeed, for any \(m = 1,2, …, M,\)
$$ p(y_i|\phi_i^{(m)};\theta)\frac{p(\phi_i^{(m)};\theta)}{p(\phi_i^{(m)}|y_i;\theta)} = p(y_i;\theta) $$
which has a zero variance, so that only one draw from \(p_{\phi_i|y_i}\) is required to exactly compute the likelihood \(p(y_i;\theta)\).
The problem is that it is not possible to generate the \(\phi_i^{(m)}\) with this exact conditional distribution, since that would require computing a normalizing constant, which here is precisely \(p(y_i;\theta)\).
Nevertheless, this conditional distribution can be estimated using the Metropolis-Hastings algorithm and a practical proposal “close” to the optimal proposal \(p_{\phi_i|y_i}\) can be derived. We can then expect to get a very accurate estimate with a relatively small Monte Carlo size M.
The mean and variance of the conditional distribution \(p_{\phi_i|y_i}\) are estimated by Metropolis-Hastings for each individual i. Then, the \(\phi_i^{(m)}\) are drawn with a noncentral student t-distribution:
$$ \phi_i^{(m)} = \mu_i + \sigma_i \times T_{i,m}$$
where \(\mu_i\) and \(\sigma^2_i\) are estimates of \(\mathbb{E}\left(\phi_i|y_i;\theta\right)\) and \(\mbox{Var}\left(\phi_i|y_i;\theta\right)\), and \((T_{i,m})\) is a sequence of i.i.d. random variables distributed with a Student’s t-distribution with \(\nu\) degrees of freedom (see section Advanced settings for the log-likelihood for the number of degrees of freedom).
Remark: The standard error of the LL on all the draws is proposed. It represents the impact of the variability of the draws on the LL uncertainty, given the estimated population parameters, but it does not take into account the uncertainty of the model that comes from the uncertainty on the population parameters.
Remark: Even if \(\hat{\cal L}_y(\theta)=\prod_{i=1}^{N}\hat{p}_{i,M}\) is an unbiased estimator of \({\cal L}_y(\theta)\), \(\hat{\cal LL}_y(\theta)\) is a biased estimator of \({\cal LL}_y(\theta)\). Indeed, by Jensen’s inequality, we have :
$$\mathbb{E}\left(\log(\hat{\cal L}_y(\theta))\right) \leq \log \left(\mathbb{E}\left(\hat{\cal L}_y(\theta)\right)\right)=\log\left({\cal L}_y(\theta)\right)$$
Best practice: the bias decreases as M increases and also if \(\hat{\cal L}_y(\theta)\) is close to \({\cal L}_y(\theta)\). It is therefore highly recommended to use a proposal as close as possible to the conditional distribution \(p_{\phi_i|y_i}\), which means having to estimate this conditional distribution before estimating the log-likelihood (i.e. run task “Conditional distribution” before).
Log-likelihood by linearization
The likelihood of the nonlinear mixed effects model cannot be computed in a closed-form. An alternative is to approximate this likelihood by the likelihood of the Gaussian model deduced from the nonlinear mixed effects model after linearization of the function f (defining the structural model) around the predictions of the individual parameters \((\phi_i; 1 \leq i \leq N)\).
Notice that the log-likelihood can not be computed by linearization for discrete outputs (categorical, count, etc.) nor for mixture models.
Best practice: We strongly recommend to compute the conditional mode before computing the log-likelihood by linearization. Indeed, the linearization should be made around the most probable values as they are the same for both the linear and the nonlinear model.
Best practices: When should I use the linearization and when should I use the importance sampling?
Firstly, it is only possible to use the linearization algorithm for the continuous data. In that case, this method is generally much faster than importance sampling method and also gives good estimates of the LL. The LL calculation by model linearization will generally be able to identify the main features of the model. More precise– and time-consuming – estimation procedures such as stochastic approximation and importance sampling will have very limited impact in terms of decisions for these most obvious features. Selection of the final model should instead use the unbiased estimator obtained by Monte Carlo.
Display and outputs
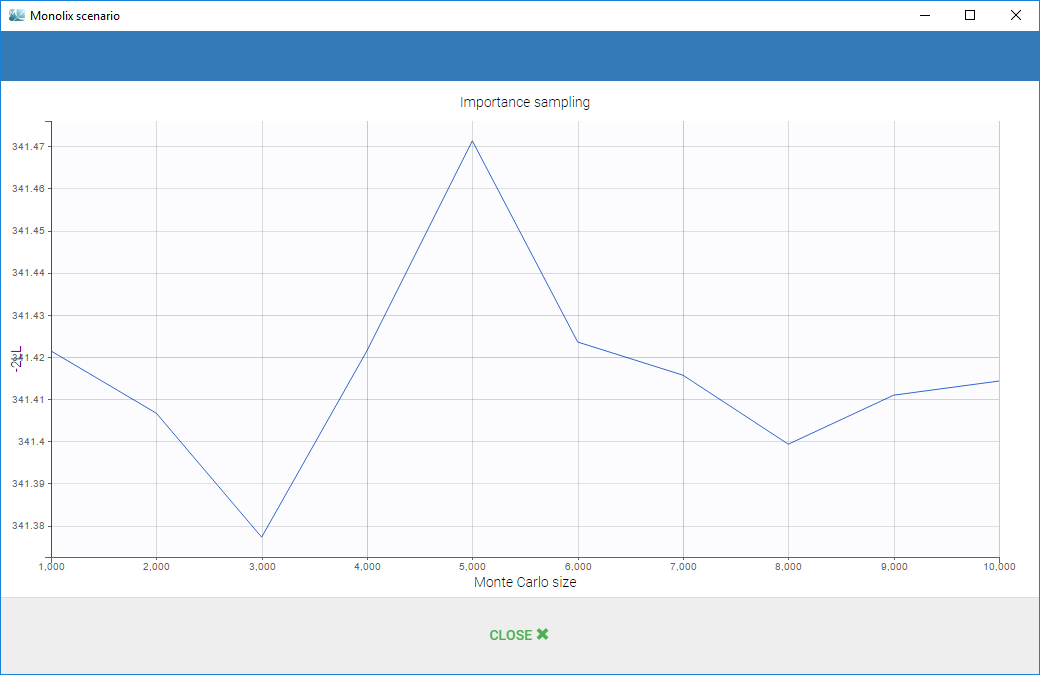
In case of estimation using the importance sampling method, a graphical representation is proposed to see the valuation of the mean value over the Monte Carlo iterations as on the following:
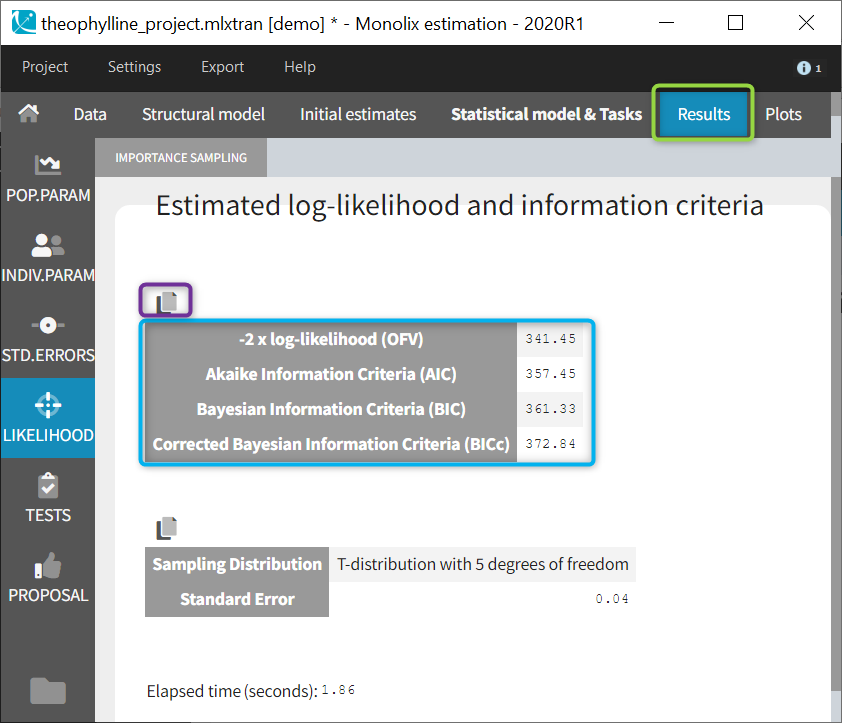
The final estimations are displayed in the result frame as below. Notice that there is a “Copy table” icon on the top of each table to copy them in Excel, Word, … The table format and display will be kept.
The log-likelihood is given in Monolix together with the Akaike information criterion (AIC) and Bayesian information criterion (BIC):
$$ AIC = -2 {\cal L}{\cal L}_y(\hat{\theta}) +2P $$
$$ BIC = -2 {\cal L}{\cal L}_y(\hat{\theta}) +log(N)P $$
where P is the total number of parameters to be estimated and N the number of subjects.
The new BIC criterion penalizes the size of \(\theta_R\) (which represents random effects and fixed covariate effects involved in a random model for individual parameters) with the log of the number of subjects (\(N\)) and the size of \(\theta_F\) (which represents all other fixed effects, so typical values for parameters in the population, beta parameters involved in a non-random model for individual parameters, as well as error parameters) with the log of the total number of observations (\(n_{tot}\)), as follows:
$$ BIC_c = -2 {\cal L}{\cal L}_y(\hat{\theta}) + \dim(\theta_R)\log N+\dim(\theta_F)\log n_{tot}$$
If the log-likelihood has been computed by importance sampling, the number of degrees of freedom used for the proposal t-distribution (5 by default) is also displayed, together with the standard error of the LL on the individual parameters drawn from the t-distribution.
In terms of output, a folder called LogLikelihood is created in the result folder where the following files are created
- logLikelihood.txt: containing for each computed method, the -2 x log-likelihood, the Akaike Information Criteria (AIC), the Bayesian Information Criteria (BIC), and the corrected Bayesian Information Criteria (BICc).
- individualLL.txt: containing the -2 x log-likelihood for each individual for each computed method.
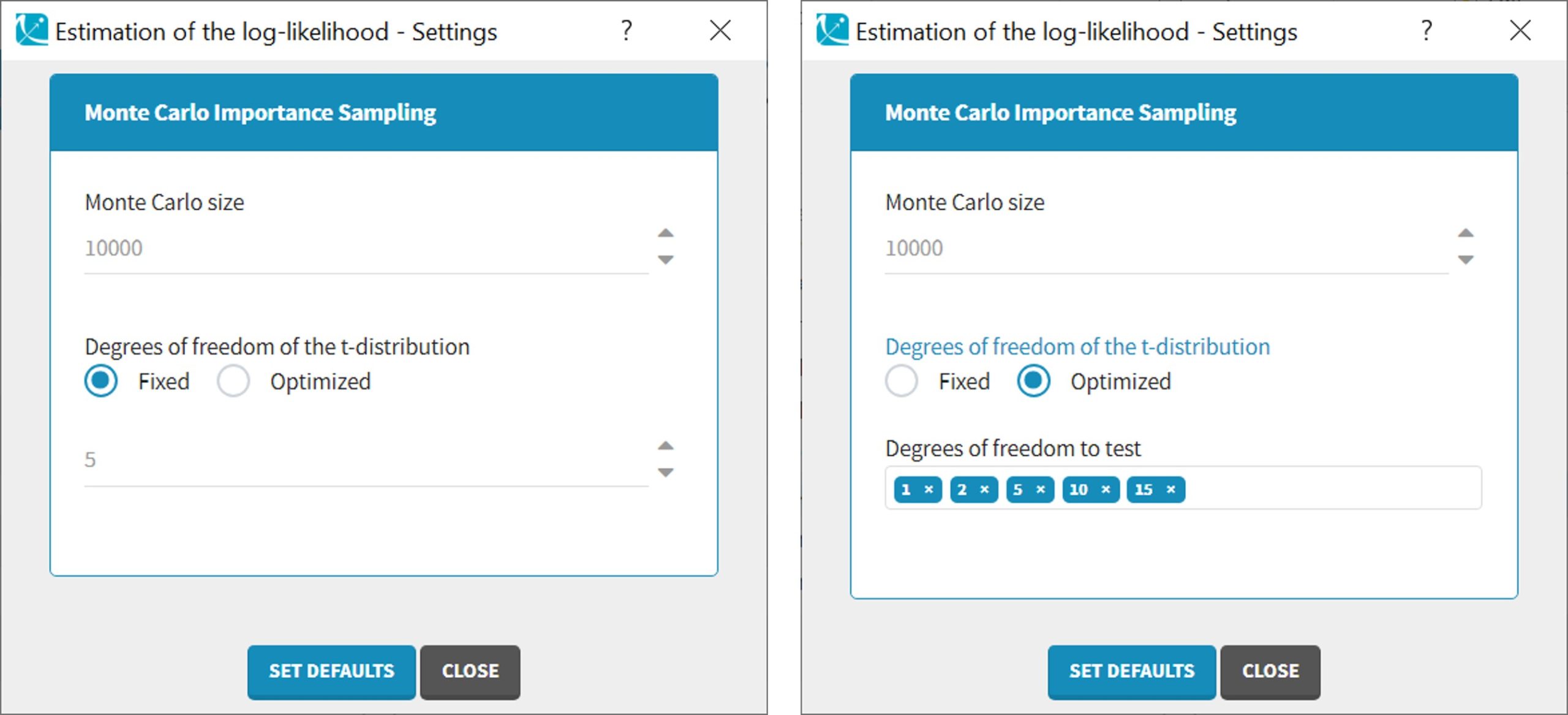
Advanced settings for the log-likelihood
Monolix uses a t-distribution as proposal. By default, the number of degrees of freedom of this distribution is fixed to 5. In the settings of the task, it is also possible to optimize the number of degrees of freedom. In such a case, the default possible values are 1, 2, 5, 10 and 20 degrees of freedom. A distribution with a small number of degree of freedom (i.e. heavy tails) should be avoided in case of stiff ODE’s defined models.