Data Format
In Monolix, a dataset should be loaded in the
Data tab to create a project.
To be accepted in the Data tab, the dataset should be in a specific format described below. If your dataset is not in the right format, in most cases, it is possible to format it in a few steps in the
data formatting tab, to incorporate the missing information.
Once the dataset is accepted and once a model is loaded, it is possible to
filter the dataset to remove outliers or focus on a particular group.
The data set format used in Monolix is the same as for the entire MonolixSuite, to allow smooth transitions between applications. In this format:
- Each line corresponds to one individual and one time point.
- Each line can include a single measurement (also called observation), or a dose amount (or both a measurement and a dose amount).
- Dosing information should be indicated for each individual in a specific column, even if it is the same treatment for all individuals.
- Headers are free but there can be only one header line.
- Different types of information (dose, observation, covariate, etc) are recorded in different columns, which must be tagged with a column type (see below).
The column types are very similar and compatible with the structure used by the
Nonmem software (the differences are listed
here). This is specified when the user defines each column type in the data set as in the following picture.
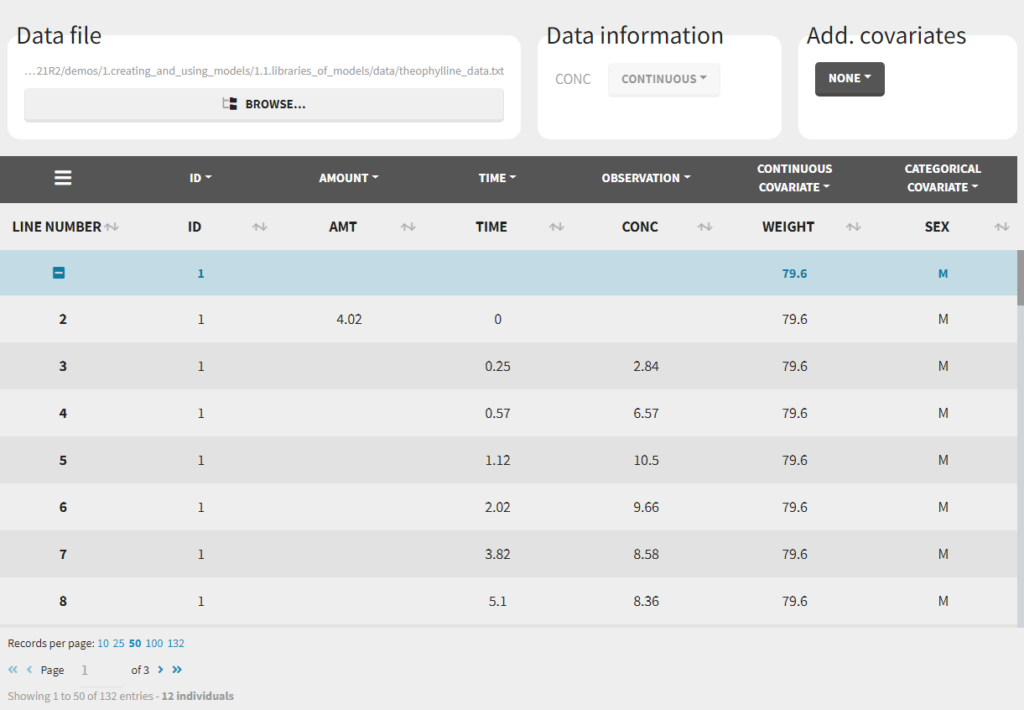
Notice that Monolix often provides an initial guess of the type of the column depending on the name.
Description of column-types
The first line of the data set must be a header line, defining the names of the columns. The columns names are completely free. In the MonolixSuite applications, when defining the data, the user will be asked to assign each column to a column-type (see here for an example of this step). The column type will indicate to the application how to interpret the information in that column. The available column types are given below.
Column-types used for all types of lines:
Column-types used for response-lines:
Column-types used for dose-lines:
Order of events
There are prioritization rules in place in case of various event types occurring at the same time. The order of row numbers in the data set is not important, and same is true for the order of administration and empty/reset macros in model files.
The sequence of events will always be the following:
- regressors are updated,
- reset done by EVID=3 or EVID=4 is performed,
- dose is administered,
- empty/reset done by macros is performed,
- observation is made.