Monolix generates a lot of different output files depending on the tasks done by the user. Here is a complete listing of the files, along with the condition for their creation and their content.
- Task: Population parameter estimation
- Task: Individual parameter estimation
- Task: Fisher Information Matrix calculation
- Task: Log-likelihood calculation
- Tests
- Tables
- ChartsData
Population parameter estimation
summary.txt
Description: summary file.
Outputs:
- Header: project file name, date and time of run, Monolix version
- Estimation of the population parameters: Estimated population parameters & computation time
populationParameters.txt
Description: estimated population parameters (with SAEM).
Outputs:
- First column (no name): contains the parameter names (e.g ‘V_pop’ and ‘omega_V’).
- value: contains the estimated parameter values.
Individual parameters estimation
All the files are in the IndividualParameters folder of the result folder
estimatedIndividualParameters.txt
Description: Individual parameters (from SAEM, mode, and mean of the conditional distribution)
Outputs:
- ID: subject name and occasion (if applicable). If there is one type of occasion, there will be an additional(s) column(s) defining the occasions.
- parameterName_SAEM: individual parameter estimated by SAEM, it corresponds to the average of the individual parameters sampled by MCMC during all iterations of the smoothing phase. When several chains are used (see project settings), the average is also done over all chains. This value is an approximation of the conditional mean.
- parameterName_mode (if conditional mode was computed): individual parameter estimated by the conditional mode task, i.e mode of the conditional distribution \(p(\psi_i|y_i;\hat{\theta})\).
- parameterName_mean (if conditional distribution was computed) : individual parameter estimated by the conditional distribution task, i.e mean of the conditional distribution \(p(\psi_i|y_i;\hat{\theta})\) . The average of samples from all chains and all iterations is computed in the gaussian space (eg mean of the log values in case of a lognormal distribution), and back-transformed.
- parameterName_sd (if conditional distribution was computed): standard deviation of the conditional distribution \(p(\psi_i|y_i;\hat{\theta})\) calculated during the conditional distribution task.
- COVname: continuous covariates values corresponding to all data set columns tagged as “Continuous covariate” and all the associated transformed covariates.
- CATname: modalities associated to the categorical covariates (including latent covariates and the bsmm covariates) and all the associated transformed covariates.
estimatedRandomEffects.txt
Description: individual random effect, calculated using the population parameters, the covariates and the conditional mode or conditional mean. For instance if we have a parameter defined as \(k_i=k_{pop}+\beta_{k,WT}WT_i+\eta_i\), we calculate \(\eta_i=k_i – k_{pop}-\beta_{k,WT}WT_i\) with \(k_i\) the estimated individual parameter (mode or mean of the conditional distribution), \(WT_i\) the individual’s covariate, and \(k_{pop}\) and \(\beta_{k,WT}\) the estimated population parameters.
Outputs:
- ID: subject name and occasion (if applicable). If there is one type of occasion, there will be an additional(s) column(s) defining the occasions.
- eta_parameterName_SAEM: individual random effect estimated by SAEM, it corresponds to the last iteration of SAEM.
- eta_parameterName_mode (if conditional mode was computed): individual random effect estimated by the conditional mode task, i.e mode of the conditional distribution \(p(\psi_i|y_i;\hat{\theta})\).
- eta_parameterName_mean (if conditional distribution was computed) : individual random effect estimated by the conditional distribution task, i.e mean of the conditional distribution \(p(\psi_i|y_i;\hat{\theta})\) . The average of random effect samples from all chains and all iterations is computed.
- eta_parameterName_sd (if conditional distribution was computed): standard deviation of the conditional distribution \(p(\psi_i|y_i;\hat{\theta})\) calculated during the conditional distribution task.
- COVname: continuous covariates values corresponding to all data set columns tagged as “Continuous covariate” and all the associated transformed covariates.
- CATname: modalities associated to the categorical covariates (including latent covariates and the bsmm covariates) and all the associated transformed covariates.
simulatedIndividualParameters.txt
Description: Simulated individual parameter (by the conditional distribution)
Outputs:
- rep: replicate of the simulation
- ID: subject name and occasion (if applicable). If there is one type of occasion, there will be an additional(s) column(s) defining the occasions.
- parameterName: simulated individual parameter corresponding to the draw rep.
- COVname: continuous covariates values corresponding to all data set columns tagged as “Continuous covariate” and all the associated transformed covariates.
- CATname: modalities associated to the categorical covariates (including latent covariates and the bsmm covariates) and all the associated transformed covariates.
simulatedRandomEffects.txt
Description: Simulated individual random effect (by the conditional distribution)
Outputs:
- rep: replicate of the simulation
- ID: subject name and occasion (if applicable). If there is one type of occasion, there will be an additional(s) column(s) defining the occasions.
- eta_parameterName: simulated individual random effect corresponding to the draw rep.
- COVname: continuous covariates values corresponding to all data set columns tagged as”Continuous covariate” and all the associated transformed covariates.
- CATname: modalities associated to the categorical covariates (including latent covariates and the bsmm covariates) and all the associated transformed covariates.
Fisher Information Matrix calculation
summary.txt
Description: summary file.
Outputs:
- Header: project file name, date and time of run, Monolix version (outputted population parameter estimation task)
- Estimation of the population parameters: Estimated population parameters & computation time (outputted population parameter estimation task). Standard errors and relative standard errors are added.
- Correlation matrix of the estimates: correlation matrix by block, eigenvalues and computation time
populationParameters.txt
Description: estimated population parameters, associated standard errors and p-value.
Outputs:
- First column (no name): contains the parameter names (outputted population parameter estimation task)
- Column ‘parameter’: contains the estimated parameter values (outputted population parameter estimation task)
- se_lin / se_sa: contains the standard errors (s.e.) for the (untransformed) parameter, obtained by linearization of the system (lin) or stochastic approximation (sa).
- rse_lin / rse_sa: contains the parameter relative standard errors (r.s.e.) in % (param_r.s.e. = 100*param_s.e./param), obtained by linearization of the system (lin) or stochastic approximation (sa).
- pvalues_lin / pvalues_sa: for beta parameters associated to covariates, the line contains the p-value obtained from a Wald test of whether beta=0. If the parameter is not a beta parameter, ‘NaN’ is displayed.
Notice that if the Fisher Information Matrix is difficult to invert, some parameter’s standard error can maybe not be computed leading to NaN in the corresponding columns.
All the more detailed files are in the FisherInformation folder of the result folder.
covarianceEstimatesSA.txt and/or covarianceEstimatesLin.txt
Description: variance-covariance matrix of the estimates for the (untransformed) parameters or transformed normally distributed parameters depending on the MonolixSuite version (see below)
Outputs: matrix with the project parameters as lines and columns. First column contains the parameter names.
The Fisher information matrix (FIM) is calculated for the transformed normally distributed parameters (i.e log(V_pop) if V has a lognormal distribution). By inverting the FIM, we obtain the variance-covariance matrix \(\Gamma\) for the transformed normally distributed parameters \(\zeta\). This matrix is then multiplied by the jacobian J (which elements are defined by \(J_{ij}=\frac{\partial\theta_i}{\partial\zeta_j}\)) to obtain the variance-covariance matrix \(\tilde{\Gamma}\) for the untransformed parameters \(\theta\):
$$\tilde{\Gamma}=J^T\Gamma J$$
The diagonal elements of the variance-covariance matrix \(\tilde{\Gamma}\) for the untransformed parameters are finally used to calculate the standard errors.

correlationEstimatesSA.txt and/or correlationEstimatesLin.txt
Description: correlation matrix for the (untransformed) parameters
Outputs: matrix with the project parameters as lines and columns. First column contains the parameter names.
The correlation matrix is calculated as:
$$\text{corr}(\theta_i,\theta_j)=\frac{\text{covar}(\theta_i,\theta_j)}{\sqrt{\text{var}(\theta_i)}\sqrt{\text{var}(\theta_j)}}$$
This implies that the diagonal is unitary. The variance-covariance matrix for the untransformed parameters \(\theta\) is obtained from the inverse of the Fisher Information Matrix and the jacobian. See above for the formula.
Log-Likelihood calculation
summary.txt
Description: summary file.
Outputs:
- Header: project file name, date and time of run, Monolix version (outputted population parameter estimation task)
- Estimation of the population parameters: Estimated population parameters & computation time (outputted population parameter estimation task). Standard errors and relative standard errors are added.
- Correlation matrix of the estimates: correlation matrix by block, eigenvalues and computation time
- Log-likelihood Estimation: -2*log-likelihood, AIC and BIC values, together with the computation time
All the more detailed files are in the LogLikelihood folder of the result folder
logLikelihood.txt
Description: Summary of the log-likelihood calculation with the two methods.
Outputs:
- criteria: OFV (Objective Function Value), AIC (Akaike Information Criteria), and BIC (Bayesian Information Criteria )
- method: ImportanceSampling and/or linearization
individualLL.txt
Description: -2LL for each individual. Notice that we only have one by individual even if there are occasions.
Outputs:
- ID: subject name
- method: ImportanceSampling and/or linearization
Tests
Tables
predictions.txt
Description: predictions at the observation times
Outputs:
- ID: subject name. If there are occasions, additional columns will be added to describe the occasions.
- time: Time from the data set.
- MeasurementName: Measurement from the data set.
- RegressorName: Regressor value.
- popPred_medianCOV: prediction using the population parameters and the median covariates.
- popPred: prediction using the population parameters and the covariates, e.g \(V_i=V_{pop}\left(\frac{WT_i}{70}\right)^{\beta}\) (without random effects).
- indivPred_SAEM: prediction using the mean of the conditional distribution, calculated using the last iterations of the SAEM algorithm.
- indPred_mean (if conditional distribution was computed): prediction using the mean of the conditional distribution, calculated in the Conditional distribution task.
- indPred_mode (if conditional mode was computed): prediction using the mode of the conditional distribution, calculated in the EBEs task.
- indWRes_SAEM: weighted residuals \(IWRES_{ij}=\frac{y_{ij}-f(t_{ij}, \psi_i)}{g(t_{ij}, \psi_i)}\) with \(\psi_i\) the mean of the conditional distribution, calculated using the last iterations of the SAEM algorithm.
- indWRes_mean (if conditional distribution was computed): weighted residuals \(IWRES_{ij}=\frac{y_{ij}-f(t_{ij}, \psi_i)}{g(t_{ij}, \psi_i)}\) with \(\psi_i\) the mean of the conditional distribution, calculated in the Conditional distribution task.
- indWRes_mode (if conditional mode was computed): weighted residuals \(IWRES_{ij}=\frac{y_{ij}-f(t_{ij}, \psi_i)}{g(t_{ij}, \psi_i)}\) with \(\psi_i\) the mode of the conditional distribution, calculated in the EBEs task.
Notice that in case of several outputs, Monolix generates predictions1.txt, predictions2.txt, …
Below is a correspondence of the terms used for predictions in Nonmem versus Monolix:
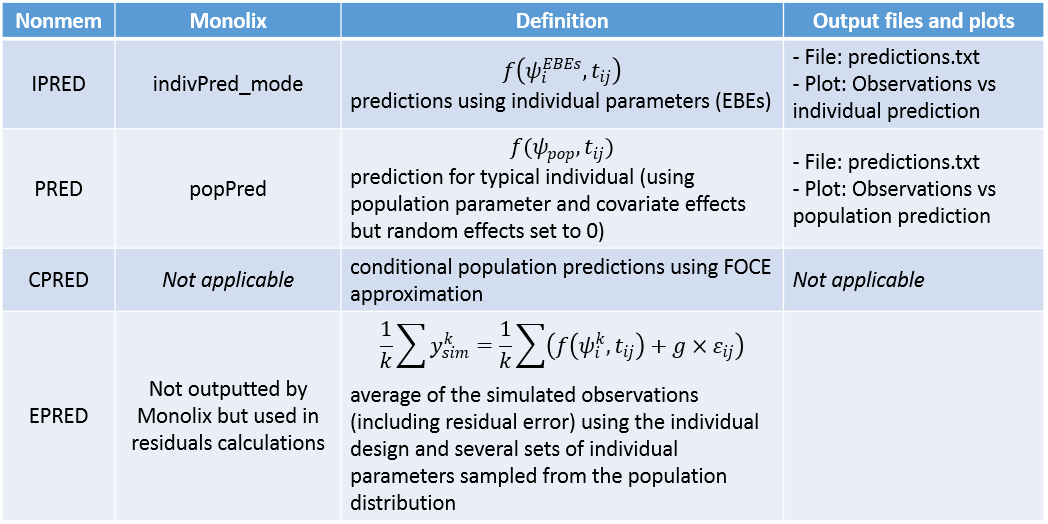
Charts data
All plots generated by Monolix can be exported as a figure or as text files in order to be able to plot it in another way or with other software for more flexibility. The description of all generated text files is described here.